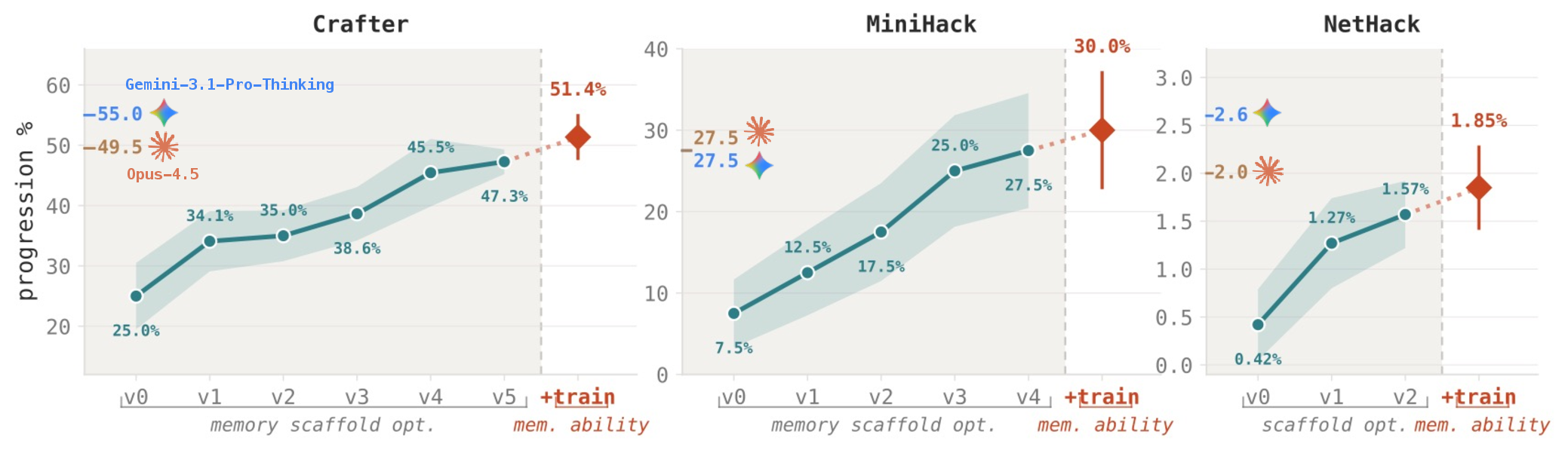
v0), AutoMem progressively improves performance through memory scaffold optimization (v0–v5 for Crafter, v0–v4 for MiniHack, v0–v2 for NetHack), followed by memory proficiency training (+train) that yields further gains on top of the optimized scaffold. Colored y-ticks mark frontier references (Gemini-3.1-Pro-Thinking, Claude-Opus-4.5).Abstract
AutoMem turns memory management into a trainable skill for LLM agents. Memory operations (read, write, search, append) live in the same action space as the agent's task actions, so the model itself decides what to store, when to retrieve, and how to organize what it knows. AutoMem automates the learning of this skill end-to-end with two meta-LLM loops: loop #1 optimizes the agent scaffold (memory structure), and loop #2 trains a dedicated memory specialist from the agent's own traces (memory proficiency). Optimizing memory alone — without ever touching the model's task-action behavior — yields ~2×–4× progression gains, lifting the open-weight Qwen2.5-32B to frontier-level performance on three long-horizon tasks: Crafter, MiniHack, and NetHack.
§The AutoMem Framework
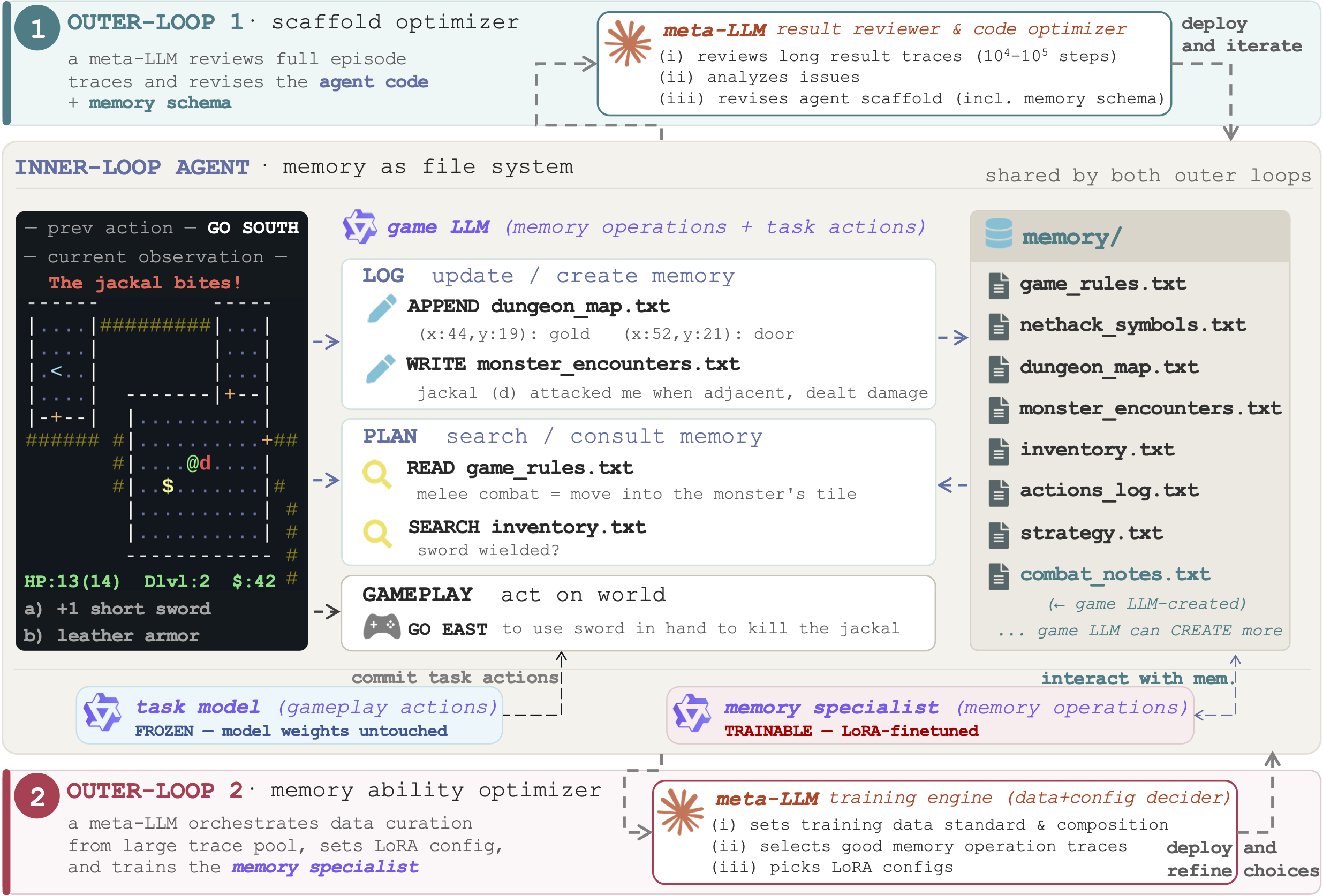
<|SEARCH|>, <|APPEND|>, <|UPSERT_MAP|>…) sit in the same action space as task actions, so every memory decision is a traceable action the outer loops can observe and optimize. Outer-loop #1 (top) optimizes the memory structure: a meta-LLM reviews full episode traces and iteratively revises the agent scaffold — its code, prompts, file schema, and action vocabulary. Outer-loop #2 (bottom) optimizes the model's proficiency: a meta-LLM training engine jointly curates SFT data from the agent's own traces and matches a LoRA configuration to train a dedicated memory specialist. At inference, the trained memory specialist handles LOG and the consultation part of PLAN, while the unmodified base gameplay model commits the world action, so memory proficiency is sharpened without ever touching the task competence. Loop #1 sets the structural ceiling; loop #2 pushes the model capacity towards it.
§Qualitative Demos: Watch the Behavior Improve
We study three stochastic, procedurally-generated worlds: Crafter — open-world survival with crafting, combat, and resource management (22 achievements, ~103 steps); MiniHack — 8 focused puzzle/navigation/combat tasks on the NetHack engine (~102 steps); and NetHack — among the hardest games, with 104–105-turn episodes regenerated every seed.
Each demo replays the same seed at each stage — v0 base scaffold, the optimized scaffold, and the trained specialist — so the world is identical and only the agent differs. The chip on each panel reports that run's progression rate (defined per environment in the note below). Press Play to advance all panels in lockstep; toggle between the Visual game view and the raw Text the model reads; memory operations the agent issued appear under every frame.
§Quantitative Results
| Agent | Crafter (%) | MiniHack (%) | NetHack (%) |
|---|---|---|---|
| Frontier proprietary — BALROG leaderboard | |||
| Gemini-3-Pro | 57.3 ±4.4 | 40.0 ±7.7 | 6.8 ±3.2 |
| Gemini-3.1-Pro-Thinking | 55.0 ±6.4 | 27.5 ±7.1 | 2.6 ±0.3 |
| Claude-Opus-4.5 | 49.5 ±3.1 | 27.5 ±7.1 | 2.0 ±0.5 |
| Gemini-2.5-Pro | 55.0 ±6.0 | 17.5 ±6.0 | 1.7 ±0.2 |
| Open-weight — BALROG leaderboard | |||
| DeepSeek-R1 (671B) | 36.4 ±3.8 | 25.0 ±6.8 | 1.4 ±0.5 |
| Qwen2.5-72B-Instruct | 27.3 ±3.6 | 5.0 ±3.4 | 0.3 ±0.3 |
| Qwen2.5-7B-Instruct | 16.4 ±3.0 | 0.0 ±0.0 | 0.0 ±0.0 |
| Qwen2.5-32B-Instruct with basic context management | |||
| sliding window | 19.55 ±3.46 | 2.50 ±2.47 | 0.00 ±0.00 |
| + chain-of-thought | 17.27 ±2.71 | 10.00 ±4.74 | 0.00 ±0.00 |
| Qwen2.5-32B-Instruct with AutoMem (ours) | |||
memory-as-file-system, v0 | 25.00 ±5.50 | 7.50 ±4.16 | 0.42 ±0.37 |
| + scaffold opt. (loop #1) | 47.27 ±2.05 | 27.50 ±7.06 | 1.57 ±0.35 |
| + memory training (loop #2) | 51.36 ±3.81 | 30.00 ±7.25 | 1.85 ±0.44 |
Progression (%), mean ± standard error over the fixed seed set (10 episodes Crafter, 5 episodes × 8 tasks MiniHack, 5 episodes NetHack). Optimizing memory alone — without modifying task-action weights — roughly doubles or more than triples performance in every environment, and the full framework yields ~2×–4× gains, approaching the level of frontier proprietary systems. Scaffold opt. is loop #1 at convergence (v5 Crafter, v4 MiniHack, v2 NetHack); + memory training adds loop #2's memory specialist on top, lifting Crafter to 51.36%, MiniHack to 30.0%, and NetHack to 1.85%.
§Why Memory Optimization Works
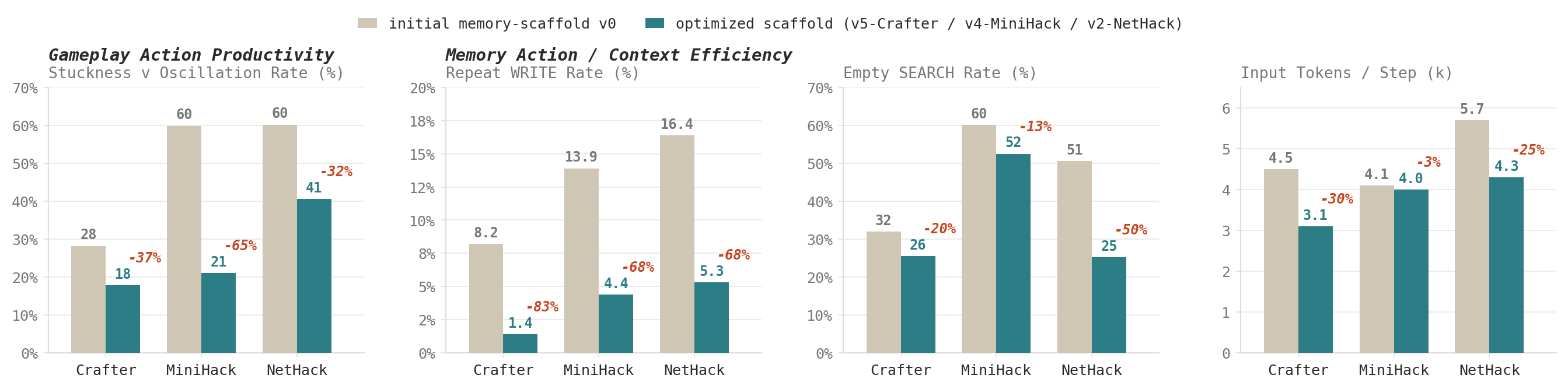
<|SEARCH|>es that return nothing) falls (−13 to −50%); and the per-step input context shrinks (−3 to −30%) as leaner memory compresses what the model must attend to. Lower is better in every panel.| LOG-phase writes / SEARCH | Base | + Trained |
|---|---|---|
| Crafter | 0.84 | 0.39 (−54%) |
| MiniHack | 2.89 | 0.82 (−72%) |
| NetHack | 4.66 | 1.31 (−72%) |
<|SEARCH|> falls in every environment (lower = more retrieval before writing): it searches existing memory before appending new content rather than logging blindly. This is the retrieval-first pattern the optimized scaffold encourages, now internalized into the model's weights.§Citation
@article{wu2026automem,
title={AutoMem: Automated Learning of Memory as a Cognitive Skill},
author={Wu, Shengguang and Zhu, Hao and Zhang, Yuhui and Wang, Xiaohan and Yeung-Levy, Serena},
journal={arXiv preprint arXiv:2607.01224},
year= {2026}
}